etBrains DataGrip 2025 是一款由 JetBrains 精心打造的数据库和 SQL 跨平台集成开发环境(IDE),专为数据库管理和 SQL 开发任务而设计,为开发人员、数据库管理员等提供了高效且全面的解决方案。

一、AI 智能助力开发
(一)基于 AI 的错误解释与架构上下文
在 DataGrip 2025 中,当用户请求 AI Assistant 解释查询时,相应的架构会自动附加到聊天中。这使得解释能利用所有相关上下文,从而更加有效。例如,开发人员在编写复杂查询遇到错误时,AI 助手可结合架构信息,精准指出错误根源,如某个表关联条件错误或者字段引用不当等,大大提升问题排查效率。
(二)支持更多尖端 LLM
聊天中的 AI 模型选择范围得到了扩展,用户可以通过选择最新、最先进的语言模型来完全掌控自己的 AI 体验。包括 Claude 3.7 Sonnet、即将推出的 OpenAI GPT - 4.1 以及 Gemini 2.0 Flash 等。不同的模型在自然语言处理能力、代码生成风格等方面各有优势,用户可根据自身需求和偏好进行选择,以获得最佳的 AI 辅助效果。例如,Claude 3.7 Sonnet 在文本理解和解释的准确性上表现出色,而 Gemini 2.0 Flash 可能在代码生成的速度和创新性上更胜一筹。
(三)免费与灵活订阅的 AI 功能
在此版本中,JetBrains AI Assistant 进行了重大升级,所有 JetBrains AI 功能在 IDE 中免费提供。其中一些功能,如无限制代码补全和本地模型支持,可以不受限制地使用;而其他功能则基于抵用金限制访问。同时,还推出了新的订阅系统,用户可以根据需要轻松扩展到 AI Pro 和 AI Ultimate 层级。这种模式既满足了基础用户免费使用部分 AI 功能的需求,又为对 AI 功能有更高要求的专业用户提供了更多选择,如专业数据库开发团队,通过订阅更高层级,可享受更强大、无限制的 AI 服务,提升整体开发效率。
二、卓越的连接性
(一)MySQL 和 MariaDB 按级别内省
为提升内省性能,MySQL 和 MariaDB 具备了不同的内省级别,加载的元数据量会根据数据库的大小自动调整。对于大型数据库,不再加载所有元数据,显著减少内省时间,让用户能够立即开始使用新连接的数据源。
内省级别介绍
级别 1:仅加载对象名称。此级别适用于数据库对象数量极大的情况,如架构对象数量大于 3,000 时(当前架构)或大于 300 时(其他架构)。不过,该级别存在一些功能限制,如无法进行修改表、外键导航、Find Usages(查找用法),以及在视图和过程文本中搜索等操作。
级别 2:加载除函数、过程、视图和事件的源代码外的所有内容。当具有源的对象数量大于 500 时(当前架构)或大于 50 时(其他架构),会自动选择此级别。它的主要缺失功能是 Find Usages(查找用法)以及在视图和过程文本中搜索的功能。
级别 3:与以前版本一样,加载所有内容,适用于所有其他情况,所有功能均按预期工作。
默认设置与调整:DataGrip 默认的内省级别值设置为 Auto select(自动选择),使用内部启发式方法检测需要加载多少元数据。若用户想恢复 DataGrip 以前的行为,可转到 DataSource properties | Options | Introspection | Default level(数据源属性 | 选项 | 内省 | 默认级别),然后选择 Level 3: Everything(级别 3: 所有内容)。用户也可根据自身经验和数据库使用情况手动选择级别,以最大程度提升 DataGrip 的性能。
(二)JetBrains 提供的.NET JDBC 驱动程序:共享内存支持 SQL Server
此 JDBC 驱动程序最初由 Rider 团队开发,从 DataGrip 2025 版本开始也可在其中使用。其主要功能是支持共享内存协议,客户端可使用此协议连接到在同一台机器上运行的 SQL Server 实例。SQL Server 的共享内存协议是最简单的协议,无需调整可配置设置即可使用,大大简化了本地 SQL Server 实例的连接过程,提高了连接效率和稳定性。
(三)以特定角色连接的功能 Oracle
在连接 Oracle 数据库时,用户现在可以在连接对话框中定义连接的特定角色。只需从 Authentication(身份验证)下拉列表中选择所需角色,即可满足不同权限下的数据库操作需求。例如,开发人员可能需要以普通用户角色进行日常开发测试,而数据库管理员则需以管理员角色进行系统配置和权限管理等操作,此功能为不同用户角色提供了更便捷、安全的连接方式。
(四)路径字段中对波浪号的支持
在 Data Sources and Drivers(数据源和驱动程序)对话框中,实现了对路径字段中波浪号(~)的支持,用于指定 SSL 证书和 BigQuery 密钥文件的目录。用户可按 Cmd+; (macOS) 或 Ctrl+; (Windows/Linux) 打开对话框,选择要更改设置的数据源,然后在 SSH/SSL 标签页的 SSL 部分使用波浪号简化路径输入。例如,用户家目录下的某个证书文件路径,可直接使用~开头快速定位,提高了配置数据源时路径设置的便捷性。
(五)从 Maven 或其他自定义仓库下载驱动程序的功能
此版本允许用户添加自定义仓库以下载驱动程序。用户只需将所需仓库添加到 ${user.home}/.m2/settings.xml 文件的 mirrors 特性中,即可从 Maven 或自定义仓库获取所需的数据库驱动程序。这为使用一些特殊或私有数据库驱动的用户提供了便利,不再局限于默认的驱动下载源,能够更灵活地满足项目中多样化的数据库连接需求。
三、高效的数据处理
(一)支持就地加载完整单元值
DataGrip 以往设置了限制每个单元加载数据量的功能,以提升大数据量表的性能。但在某些场景下,用户需要加载所有数据,现在这一需求得以满足。用户只需将鼠标悬停在单元上,然后在快速操作弹出工具栏中点击 Load Full Cell(加载完整单元),即可获取该单元的全部数据,方便对特定数据进行完整分析,如查看完整的长文本字段内容或复杂的 JSON 格式数据。
(二)地理类型数据显示(PostgreSQL、MySQL、MariaDB)
对于 PostgreSQL、MySQL 和 MariaDB 空间数据库,DataGrip 现在能够在网格中正确显示原始地理类型值。这对于涉及地理信息系统(GIS)开发或处理地理空间数据的用户非常重要,使他们能够直观地查看和处理地理数据,如地图坐标、区域边界等信息,无需额外的数据转换或处理工具,提高了地理数据处理的效率和准确性。
(三)支持带有微秒的时间戳(BigQuery)
在 BigQuery 数据处理中,用户若想查看以微秒为单位显示的时间戳,只需右键点击列标题并导航到 Change Display Type(更改显示类型),选择相应的显示类型即可。这一功能满足了对时间精度要求较高的应用场景,如金融交易记录、科学实验数据记录等,确保时间数据的完整性和准确性展示,方便用户进行更精确的数据分析和处理。
四、贴心的编码辅助
在使用临时表时,针对 Oracle 和 SQLite 数据库,DataGrip 现在会建议用户切换到 Single session mode(单会话模式)。此模式允许用户在数据库资源管理器中查看这些临时表,避免因会话问题导致临时表数据丢失或无法查看,提高了临时表使用的便捷性和数据安全性,尤其是在多会话并发操作较为复杂的数据库环境中,为开发人员提供了更贴心的编码辅助。
五、广泛的数据库支持
DataGrip 支持众多数据库类型,包括但不限于 PostgreSQL、MySQL、Oracle、Microsoft SQL、MongoDB、Redis、Azure SQL、Amazon Redshift、Amazon DynamoDB、SQLite、IBM Db2、H2、Sybase ASE、Exasol、Apache Derby、MariaDB、HyperSQL、Snowflake、Apache Cassandra、ClickHouse、Greenplum、Apache Hive、Opentext、CockroachDB、Couchbase、Google BigQuery 等。无论用户使用的是流行的关系型数据库,还是新兴的 NoSQL 数据库,都能通过 DataGrip 进行统一管理和操作,无需在不同工具和界面之间频繁切换,大大提高了工作效率。
六、其他实用功能
(一)智能查询控制台
DataGrip 的查询控制台允许用户以不同模式执行查询,如只读模式、编辑器中的结果模式和手动事务提交模式等。同时,通过本地历史记录功能,用户可以跟踪所有活动,防止工作成果丢失。例如,在进行复杂的数据库查询测试时,用户的每一次查询操作及其结果都会被记录,方便后续查看和对比分析。
(二)代码补全
提供上下文相关的代码补全功能,能够识别表结构、外键,甚至是在编辑代码中创建的数据库对象,帮助用户更快速地编写 SQL 代码。比如,当用户输入 “SELECT” 后,DataGrip 会根据当前数据库架构,自动补全可能的表名、字段名等,减少了代码输入量,提高了编写效率和准确性。
(三)多种格式导入 / 导出
支持从脚本文件、CSV、TSV 或具有分隔符分隔值的文本文件导入数据,也可以将数据导出为 CSV、JSON、HTML、Markdown、Excel 等多种格式,用户甚至可以自行创建格式。在数据迁移、备份或与其他系统共享数据时,这种多样化的导入 / 导出功能提供了极大的便利,满足了不同场景下的数据交互需求。
(四)实时分析和快速修复
能够检测代码中可能存在的 bug,并即时建议最佳修正选项。它会立即提示用户未解决的对象,如未定义的表、字段等,并提供解决问题的方式。在代码编写过程中,实时分析功能就像一个智能助手,随时帮助用户发现并解决潜在问题,提高代码质量。
(五)查询历史记录
将所有查询保留在日志文件中,支持具有可自定义模式和 SQL 方言选项的参数化 SQL 查询。这使得用户可以方便地回顾历史查询,复用之前的查询语句,或者分析查询执行情况,优化查询性能。例如,数据库管理员可以通过查询历史记录,查看一段时间内的高频查询,对其进行性能优化,提升数据库整体运行效率。
(六)版本控制集成
为 Git、SVN 和 Mercurial 等所有主流版本控制系统提供统一支持,方便团队协作开发。在多人协作开发数据库项目时,开发人员可以直接在 DataGrip 中进行版本控制操作,如提交代码、拉取更新、查看版本历史等,确保数据库代码的一致性和可追溯性,避免因代码冲突导致的开发问题。
(七)UI 和主题定制
提供浅色和深色主题、全彩自定义、可定制的按键映射和语言插件等,用户可以根据自己的偏好调整工具的外观和配置。例如,长时间在夜间工作的用户可以选择深色主题,减少眼睛疲劳;习惯特定快捷键操作的用户可以自定义按键映射,提高操作效率;非英语母语用户可安装语言插件,使界面语言更符合自身使用习惯。
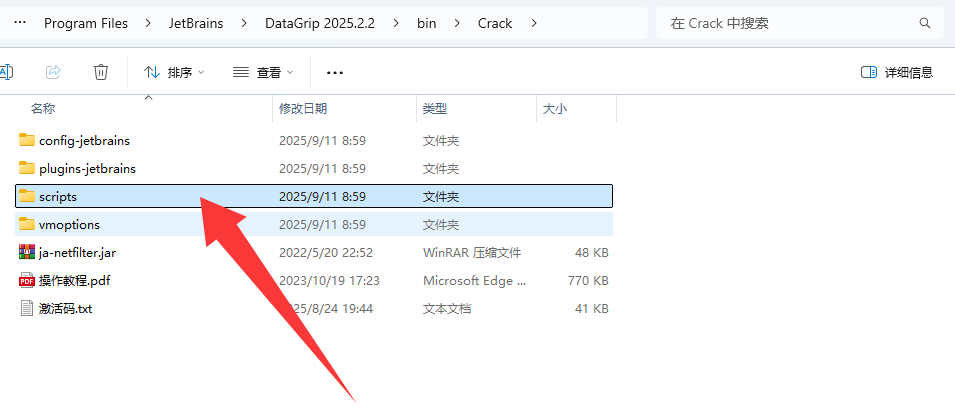
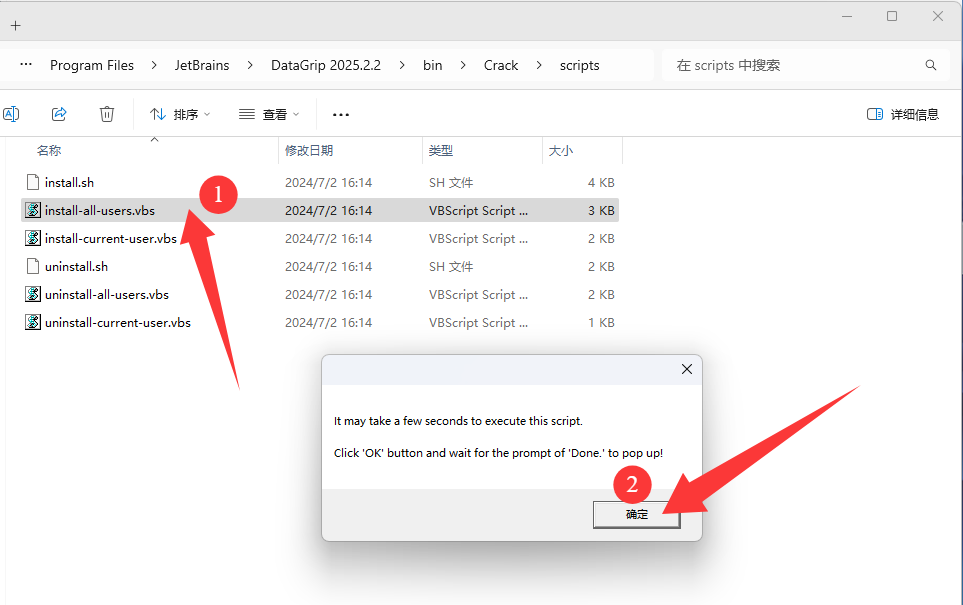
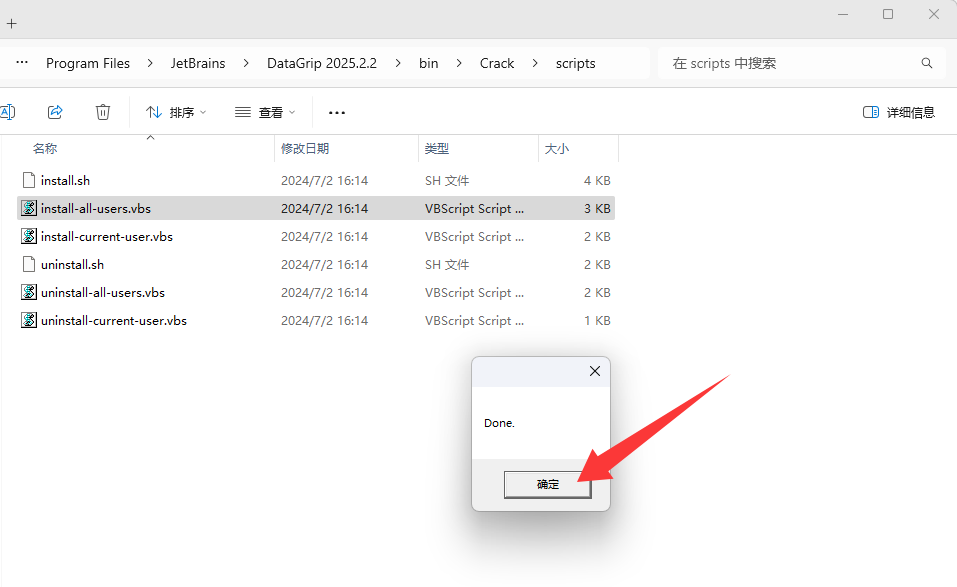

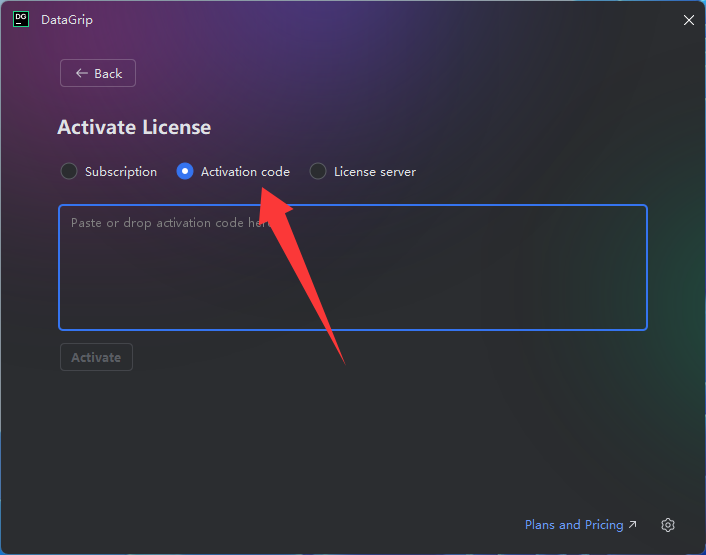



*有问题的链接ID:

再次使用微信扫一扫授权登录



 个人中心
个人中心 我的消息
我的消息 我的收藏
我的收藏 账号设置
账号设置

 普通下载
普通下载 悬赏问答
悬赏问答

 在线客服
在线客服

